谷歌昨夜放深度学习大招!TensorFlow六大重磅升级
谷歌昨夜放深度学习大招!TensorFlow六大重磅升级
智东西3月7日消息,今日凌晨,全球机器学习开发者期待的TensorFlow开发者峰会(TensorFlow Dev Summit 2019)在美国加州桑尼维尔市Google Event Center举行,这场机器学习盛会已经举办到了第三届,这也是迄今为止最大的一届开发者峰会。
在本次大会上,TensorFlow团队发布了开源机器学习框架TensorFlow 2.0 Alpha版本,谷歌称其更加简单直观易用。新版本使用Keras高级API来简化框架的使用,许多被视为冗余的API(例如Slim和Layers API等非面向对象层API)将被弃用。该版本计划在今年第二季度全面发布,用户现在可以抢先体验。
另外,TensotFlow团队还在今天推出了三款新硬件产品,发布了两大主攻隐私问题的新工具TensorFlow Federated和TensorFlow Privacy,并公布了关于TensorFlow js 1.0,Swift for TensorFlow 0.2,TensorFlow Extended(TFX)等前沿的最新研究成果及TensorFlow应用案例的分享。
就连TensorFlow的logo也从过去的三维积木状,变成了扁平化风格的“T”和“F”字母拼接。
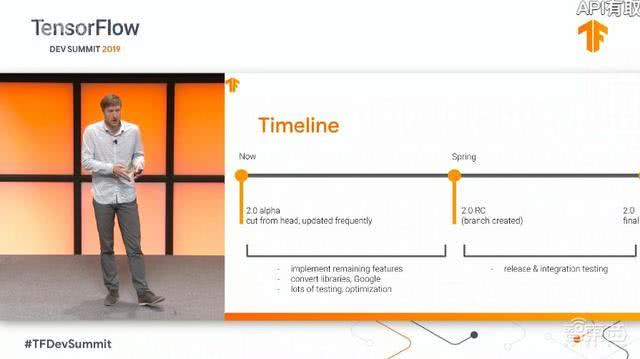
TensorFlow 2.0 Alpha版本重大升级
TensorFlow工程总监Rajat Monga表示,自2015年11月推出以来,TensorFlow总下载量超过4100万次,提交了5万多次代码更新,目前已有1800多名来自全世界的贡献者。
根据此前谷歌释放的消息,TensorFlow 2.0将是一个重要里程碑,将易用性提升到新的高度。
今年1月,谷歌放出TensorFlow 2.0开发者预览版,当时谷歌AI团队的Martin WIcke在TensorFlow官方社区发帖称,测试版还不完整、不够稳定、功能不完整、很多地方和TensorFlow 1.0不通用。因此今日发布的TensorFlow 2.0 Alpha备受开发者期待。
TensorFlow 2.0使用Keras作为开发者的核心体验,将Keras API指定为构建和训练深度学习模型的高级API,弃用其他API。另外,2.0改进了“开箱即用”的性能,用户可如常使用Keras,利用Sequential API 构建模型,然后使用 “compile” 和 “fit”,tensorflow.org中所有常见的”tf.keras”示例均可在2.0中便捷使用。同时,2.0版本也为需要更高灵活性的开发者提供更多选择。
其中最适合机器学习起步的是tf.keras Sequential API,使用这款API,不需要很多代码就能写出一个神经网络,实践中95%的机器学习问题都适用。但这一API仅适用于搭建小模型,还需要更强可扩展性的工具。
为了进一步提升用户的可用性,去年首次推出的Eager execution(一个用于机器学习的实验和研究平台)成为TensorFlow 2.0的核心功能。它通过TensorFlow实践更好地调整了用户对编程模型的期望,使TensorFlow更容易被学习和应用。
TensorFlow 2.0是“Eager 优先”,这意味着op在被调用后会立即运行。在TensorFlow 1.x中,用户可能会先基于图执行,然后通过 “tf.Session.run( )”执行图的各个部分,而TensorFlow 2.0从根本上将流程简化,使得同样出色的op更易被理解和使用。
“Eager execution” 还有助于原型制作、调试和监控运行中的代码,用户可使用Python调试程序检查变量、层及梯度等对象,并利用装饰器 “@tf.function”中内置的Autograph直接获取图表优化和效率,非常方便。
“我们过去只使用TensorFlow图。大约一年前,我们启动了eager execution。”Monga称,使用eager execution和tf.function可以保留1.x版本基于图执行的所有优点,包括性能优化、远程执行以及轻松序列化、导出和部署的能力,同时又提供了Python的灵活性和易用性,以及非常好的API。
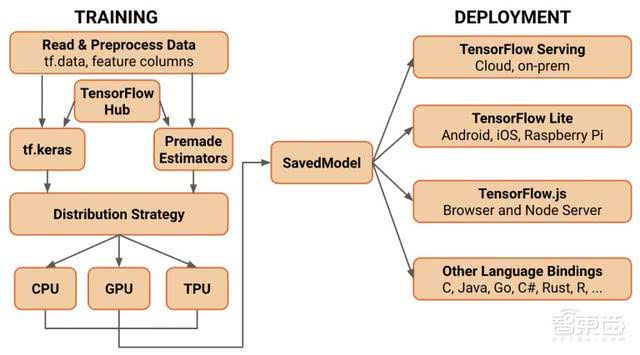
下图是一个工作流程示例,简单的说,就是先使用tf.data创建的输入线程读取训练数据,其次用tf.Keras或Premade Estimators构建、训练和验证模型,接着用eager execution进行运行和调试。
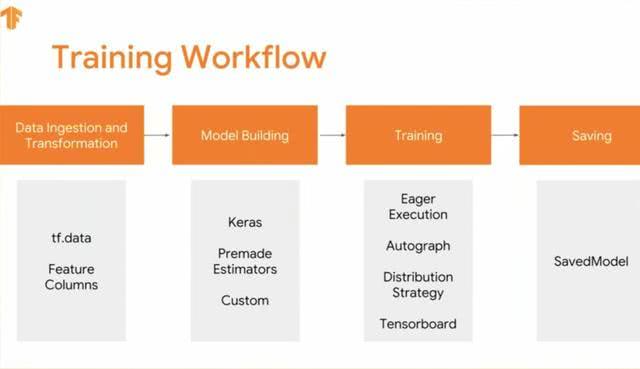
然后在图形上使用tf.function将Python程序转换成TensorFlow图,再使用Distribution Strategy API在不更改模型定义的情况下,基于CPU、GPU等不同硬件配置上分布和训练模型,最后导出到SavedModel实现标准化。
当然,用户也可以单独使用tf.keras.layers自行编写梯度和训练代码,或者单独使用 tf.keras.optimizers、tf.keras.initializers、tf.keras.losses以及tf.keras.metrics等。

此外,TensorFlow 2.0完全支持Estimator,并带来一些新功能,比如允许研究人员和高级用户使用丰富的扩展 ( 如 Ragged Tensors,TensorFlow Probability,Tensor2Tensor 等) 进行实验。
谷歌会提供一个转换工具和指导文档,以帮助用户实现从TensorFlow 1.x到2.0版本的过渡。同样,Tensorflow.org也对新的内容和资源进行了修订。
明天会有相关Workshop讨论更具体的兴趣,感兴趣的小伙伴不妨定好闹钟准时看直播。
如果想要快速上手TensorFlow 2.0 Alpha 版,可前往TensorFlow的新网站https://www.tensorflow.org/alpha,找到Alpha版的教程和指南。Alpha版文档中的每个教程均会自动下载并安装TensorFlow 2.0 Alpha版,并会在后续提供更多内容。
推出适用于移动和嵌入式设备的TensorFlow Lite 1.0
接下来, TensorFlow工程总监Raziel Alvarez介绍了适用于移动开发人员的TensorFlow Lite 1.0的相关进展。

TensorFlow Lite于2017年5月在谷歌I/O开发者大会上首次推出,是TensorFlow针对移动和嵌入式设备的轻量级解决方案,提供了在Android、iOS和Raspberry Pi以及Edge TPU等嵌入式系统上部署模型的能力。
机器学习过去跑在服务器上,如今越来越多地应用于手机、汽车等移动设备上。而将机器学习部署到这些边缘设备,除了要考虑音频、图像等数据的隐私问题外,在设计模型时还要考虑有没有足够计算力、设备能提供多少资源、存储能力和电池限制如何等问题。
TensorFlow Lite的主要优势通过探索量化、delegate等各种技术,能大大压缩AI模型大小,并且可在本地部署,在加速器硬件不可用时能够力挽狂澜,返回至经过优化的CPU执行操作,从而确保模型在任何设备上快速运行。

不过它在模型转换方面也遇到过一些问题,比如ops不全面,对RNN的控制流等语义不支持等。不过如今这些问题得到改善,它现在可支持上百种ops并支持控制流。
TensorFlow Lite可为CPU、GPU和Edge TPU均能带来显著的提速效果。目前1.0版本支持对Edge TPU、GPU delegate和安卓神经网络delegate的加速,针对Arm和x86的CPU优化的加速也正在进行中。
1月份开发人员预览版中提供了许多设备代表的移动GPU加速功能。它可以使模型部署比浮点CPU快2到7倍。Edge TPU代表能够将速度提高到浮点CPU的64倍。

今天TensorFlow Lite for ML已经运行在20亿台移动设备上,应用到谷歌搜索、谷歌助手、Pixel Visual Core等诸多原生谷歌应用和服务、以及谷歌合作伙伴的产品中。
以谷歌助手为例,谷歌助手已经被用于10亿设备,这要求神经网络必须在任何设备都能使用,而且不仅要保证每次实时运行的延迟率极低,同时在离线状态也能高速运行大型模型。当谷歌助手需要在离线时响应查询时,所有CPU模型的计算都由TensorFlow Lite执行。
据谷歌助手工程师介绍,尽管此前谷歌助手在边缘设备的神经网络训练方面已经投入了很多研发,但基于TensorFlow Lite更出色的性能表现,他们还是在去年决定迁移到TensorFlow Lite中。

另一个例子是累计有8亿用户的网易有道,从有道词典、有道翻译官到U-Dictionary,每款广受欢迎的线上产品都运用了OCR识别等AI技术。TensorFlow Lite帮助网易有道将线下图片翻译(把图片中的文本翻译成另一种语言)提速30%-40%。
在未来,谷歌计划普遍提供GPU detegate,扩大覆盖范围并最终确定API。Raziel Alvarez表示,未来还会提供更多指南文件,并在网站上分享未来发展路线图。同样,Tensorflow Lite 1.0的更多细节会在明天的Workshop中披露。

另外,TensorFlow Lite还可以在Raspberry Pi和谷歌在今天推出的Coral Dev Board等设备上运行。
Coral开发板(Coral Dev Board)是谷歌新推出的一款硬件产品,售价150美元,具有可移动的模块化系统和一个Edge TPU AI芯片,能够以每秒30帧的速度在高分辨率视频上“同时执行”深度前馈神经网络。

除了Coral Dev Board,谷歌还推出了另外两款硬件产品,分别是售价74.99美元的Coral USB加速器和售价24.99美元的500万像素相机配件。
Coral USB加速器包含Edge TPU、32位Arm Cortex-M0 +微处理器、16KB闪存和2KB RAM,可以在任何64位Arm或Debian Linux支持的x86平台上以USB 2.0速度运行,旨在加速现有树莓派和Linux系统的机器学习推理。
在此之前,英特尔曾于几年前就发布了USB神经网络加速计算棒,不过当时那款神经计算棒只支持Caffe,而Coral USB加速器支持Caffe、TensorFlow和ONNX。

相机由Omnivision制造,有一个1.4微米的传感器,具有1/4英寸光学尺寸和2.5mm焦距,并通过一个连接到开发板。除了自动曝光控制、白平衡、带通滤波和黑电平校准外,它还具有可调色彩饱和度、色调、伽玛、锐度、镜头校正、像素消除和噪声消除功能。
作为公测的一部分,这三款产品均已在谷歌的Coral店面上发售。Coral Dev Board的SOM和Coral USB加速器的PCle版本均可批量购买。谷歌还宣布它将很快发布基板原理图。

发布面向隐私的两大新工具
紧随TensorFlow 2.0 Alpha之后,TensorFlow Federated(TFF)和TensorFlow Privacy也来了。
TFF是是一个开源框架,用于试验针对分散式数据的机器学习和其他计算。它采用的是一种名为联合学习(FL)的方法,许多参与的客户端可训练共享的 ML 模型,同时将数据保存在本地。
TensorFlow团队根据在谷歌开发联合学习技术时积累的经验设计了TFF,而谷歌可以为 ML 模型进行 移动键盘检索和设备内搜索提供支持。通过 TFF,TensorFlow可为用户提供更加灵活开放的框架,使其可以通过该框架在本地模拟分散式计算。
TensorFlow Federated链接:https://www.tensorflow.org/federated/federated_learning

TensorFlow Privacy是一个TensorFlow机器学习框架库,旨在让开发人员更容易培训具有强大隐私保障的AI模型。谷歌表示它可以在开源中使用,并且使用标准TensorFlow机制的开发人员不应该更改其模型体系结构或训练过程。
根据谷歌的统计技术,TensorFlow Privacy基于差异隐私原则运作,旨在最大限度地提高准确性,同时平衡用户信息。为了确保这一点,它使用改进的随机梯度下降优化模型,将训练数据示例引起的多个更新平均化并进行对应的剪切,并将噪声添加到最终平均值。
谷歌表示,计划将TensorFlow Privacy发展成为培训机器学习模型的最佳技术中心,并提供强大的隐私保障。
TensorFlow Privacy Github地址:https://github.com/tensorflow/privacy
除此之外,从服务器、边缘设备到网络,TensorFlow通过标准化交换格式和调整API实现平台和组建间的兼容性和一致性,支持更多平台和语言。
TensorFlow for Java已经有30万次下载和100个贡献者。今天公布的TensorFlow.js1.0版本性能进一步优化,例如和去年相比,为浏览器中MobileNet v1推理带来了9倍提升,还有一些新的现成模型可供Web开发人员整合到应用程序中,并支持更多运行Java的平台。Swift for TensorFlow软件包也更新到0.2版本,可用性再度提升。
为了帮助开发人员和有兴趣学习如何使用TensorFlow 2.0的人们,谷歌正在与多个在线学习课程合作。Fast.ai正在使用Swift for TensorFlow创建一个ML课程,Udacity和Coursea的课程则主要针对初学者。
Udacity的“TensorFlow深度学习简介”课程自2016年推出以来,已有超过40万名学生参加。
Deeplearning.ai计划开设的“TensorFlow:从基础知识到掌握专业化”系列课程将由Laurence Moroney博士教授。Moroney与Coursera联合创始人和Deeplearning.ai联合创始人Andrew Ng合作开发课程和教学大纲,旨在帮助开发人员培训,理解和改进他们的神经网络。
此外,今天谷歌还为移动开发人员推出了TensorFlow Lite的Fast.ai培训课程。
结语:TensorFlow的变中求生
自2015年11月问世以来,TensorFlow迅速成长为机器学习领域最受欢迎的框架之一。根据2018年的Octoverse报告,TensorFlow维护着GitHub上贡献者数量最多的开源项目。但Pytorch等后起之秀势头相当之猛,TensorFlow的地位并没有那么稳固。
此前TensorFlow 1.x因为相对混乱的API而饱受诟病,2.0版本采用的“Eager 优先”策略毫无疑问将明显将改善这一问题。不过同时这也意味着,一大批TensorFlow老用户要开始改变思维模式来适应新版本的变化。至于其易用性究竟增强到什么程度,还要看用户的实际体验。
Rajat Monga
最新事件